A customer calls your contact center and reads out their credit card number to an agent. A prospect joins a sales call and shares their name, work email, and company. Both conversations are recorded and transcribed, and both now contain sensitive personal data sitting in plain text in your database.
AssemblyAI Review: Is This Speech AI Platform the Right Choice in 2026?
AssemblyAI has become one of the most recognized names in the speech-to-text and audio intelligence space. With over 5,000 customers and millions of API calls processed daily, it has established itself as a comprehensive solution for developers and enterprises looking to extract value from audio data. The platform combines accurate transcription with a suite of audio intelligence features, plus a unique framework for applying Large Language Models to speech.
AssemblyAI Review: Is This Speech AI Platform the Right Choice in 2026?
Published on Feb 25, 2026
By Matija Laznik
AssemblyAI has become one of the most recognized names in the speech-to-text and audio intelligence space. With over 5,000 customers and millions of API calls processed daily, it has established itself as a comprehensive solution for developers and enterprises looking to extract value from audio data. The platform combines accurate transcription with a suite of audio intelligence features, plus a unique framework for applying Large Language Models to speech.
This AssemblyAI review is based on an in-depth analysis of the platform. AssemblyAI is the ideal choice if:
You need a comprehensive voice AI platform with deep LLM integration
You're building applications that require advanced audio analysis
You want access to an extensive Audio Intelligence suite through a single API
You value an established platform with enterprise-grade compliance
Your primary real-time use cases involve English or a handful of major European languages.
However, AssemblyAI might not be the best choice if:
You need extensive multilingual support for real-time streaming beyond six languages
You're working with conversations that frequently switch between multiple languages in real-time
You prefer all audio intelligence features included in base pricing rather than modular add-ons
You want a recurring monthly free tier rather than a one-time credit allocation
You're building voice agents and prefer an infrastructure partner that won't expand into competing solutions
The sections below cover each of these areas in detail, including a look at Gladia as an alternative for teams whose priorities lean toward multilingual real-time performance and all-inclusive pricing.
Table of Contents:
What is AssemblyAI?
AssemblyAI Pros & Cons
AssemblyAI Review: How It Works & Key Features
Where AssemblyAI Falls Short
Top AssemblyAI Alternative: Gladia
AssemblyAI or Gladia: Comparison Summary
Final Verdict
What is AssemblyAI?
AssemblyAI is an AI-powered platform that provides advanced models for transcribing and understanding speech through an API.
Founded in 2017 by Dylan Fox, the company is now headquartered in San Francisco. The platform was born from Fox's frustration with existing speech recognition tools during his time as a machine learning engineer at Cisco. He found the developer experience poor and the APIs difficult to access.
The platform has grown significantly since then, now employing over 100 people and having raised $115 million in funding.
AssemblyAI's services are organized into three main areas: Speech-to-Text for converting audio into written text, Audio Intelligence for extracting insights like speaker identification and sentiment analysis, and LeMUR for applying Large Language Models to transcribed speech data.
AssemblyAI positions itself as a developer-first platform, offering robust documentation and SDKs for Python and JavaScript, with Java and Go SDKs available in maintenance mode. The company serves a wide range of customers, from startups building voice-enabled applications to large enterprises that require scalable transcription and analysis capabilities.
The ideal AssemblyAI user is a developer or enterprise with significant audio data that needs both accurate transcription and deeper analytical capabilities, particularly those interested in leveraging LLMs for complex tasks like summarization and question-answering on audio content.
AssemblyAI pros & cons
Pros
Cons
High transcription accuracy with specialized models
Cost can escalate for high-volume use cases with add-ons
Comprehensive Audio Intelligence suite in one API
Real-time streaming supports fewer languages than async
LeMUR framework for LLM-powered audio analysis
Learning curve for advanced LeMUR features
Well-documented API with multiple SDK options
Default participation in model training program
Enterprise compliance (SOC 2, HIPAA, ISO 27001)
Modular pricing can become complex
99.9% uptime guarantee for contracted customers
Expanding into end-to-end voice AI solutions
AssemblyAI review: how it works & key features
Core transcription: high accuracy with automatic formatting
AssemblyAI's transcription engine, powered by models like Universal-2 and the newer Universal-3 Pro, converts audio and video files into text with automatic punctuation and proper casing.
The system supports both pre-recorded files and real-time streaming audio. Users can upload files directly or provide URLs, and the API returns structured JSON responses with the transcript, word-level timestamps, and confidence scores.
Word-level timestamps are included by default, providing millisecond-resolution timing for each word (with accuracy typically within about 400 milliseconds). This is useful for generating subtitles, creating interactive transcripts, or aligning text with audio for detailed analysis.
AssemblyAI offers a suite of Audio Intelligence features that analyze the transcribed text to extract meaningful insights. These features can be enabled through parameters in the API request.
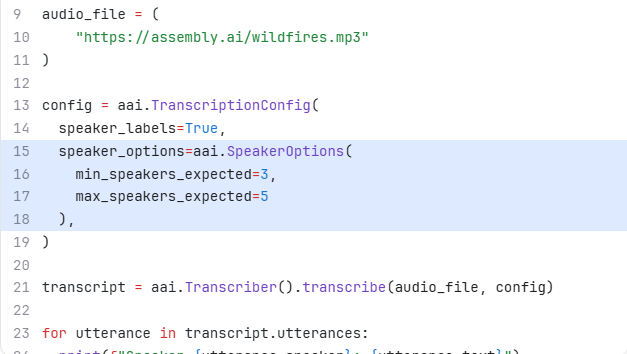
Speaker Diarization identifies and labels different speakers in a conversation. Users can specify the expected number of speakers to improve accuracy.
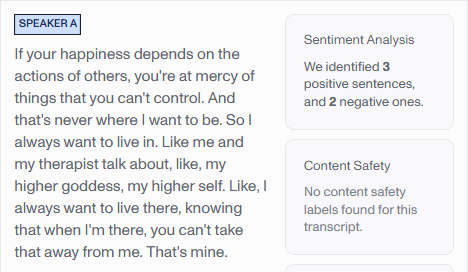
Sentiment Analysis classifies each sentence as positive, negative, or neutral, providing confidence scores for each classification. When combined with speaker diarization, sentiment can be attributed to specific speakers.
Summarization generates concise summaries of transcripts with different formats available: a brief "gist," bullet points, a headline, or a paragraph summary. The feature supports both informative and conversational summary styles.
Content Moderation detects sensitive topics including hate speech, violence, and other categories, providing severity scores for flagged content.
PII Redaction identifies and removes personally identifiable information from transcripts, with options to replace sensitive data with hash symbols or entity type labels.
Entity Detection recognizes named entities like people, organizations, locations, and dates, returning the detected entities with their timestamps and categories.
LeMUR: large language models for speech data
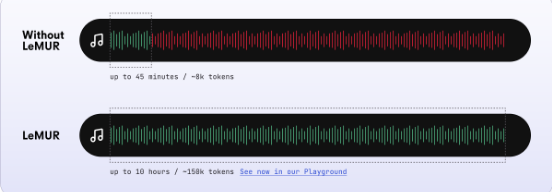
LeMUR (Leveraging Large Language Models to Understand Recognized Speech) is AssemblyAI's framework for applying Large Language Models to transcribed speech. This feature addresses a common challenge: most LLMs have limited context windows that make processing long audio recordings difficult.
LeMUR can handle transcripts from audio files up to 10 hours in length, equivalent to approximately 150,000 tokens. It achieves this through intelligent segmentation, vector database indexing, and advanced prompting techniques.
The framework offers several capabilities: customizable summaries with user-defined formats, question-answering on transcript content, and action item extraction. Users can inject custom context into requests to improve relevance (for example, providing a sales playbook to help evaluate a sales call).
LeMUR works with Anthropic's Claude models, with pricing based on token usage. For users who need access to multiple LLM providers, including GPT and Gemini models, AssemblyAI offers a separate LLM Gateway feature.
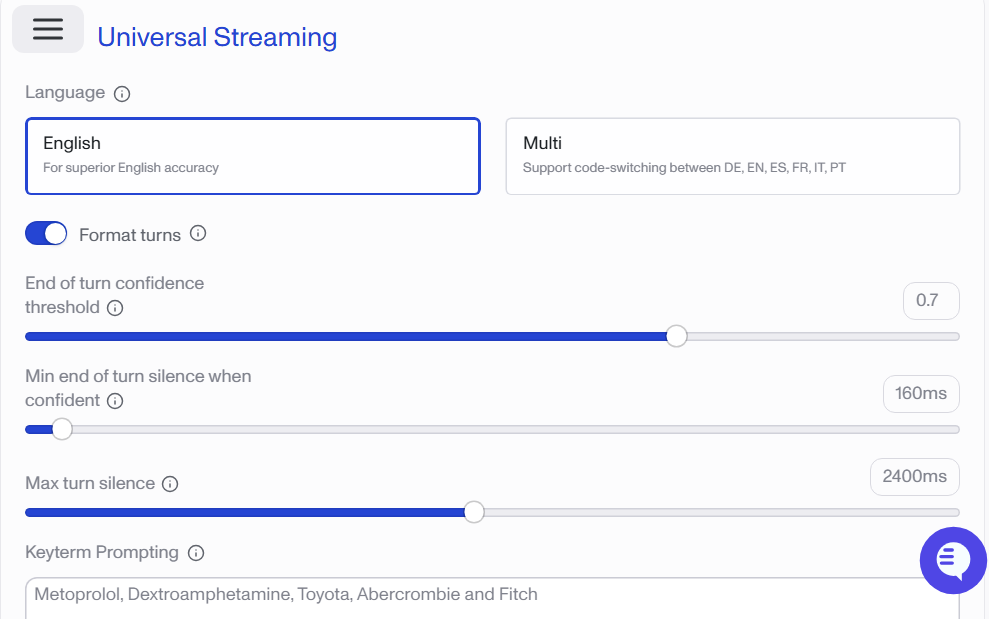
Real-time transcription: streaming with low latency
AssemblyAI's real-time transcription operates through WebSocket connections, processing audio as it's captured.
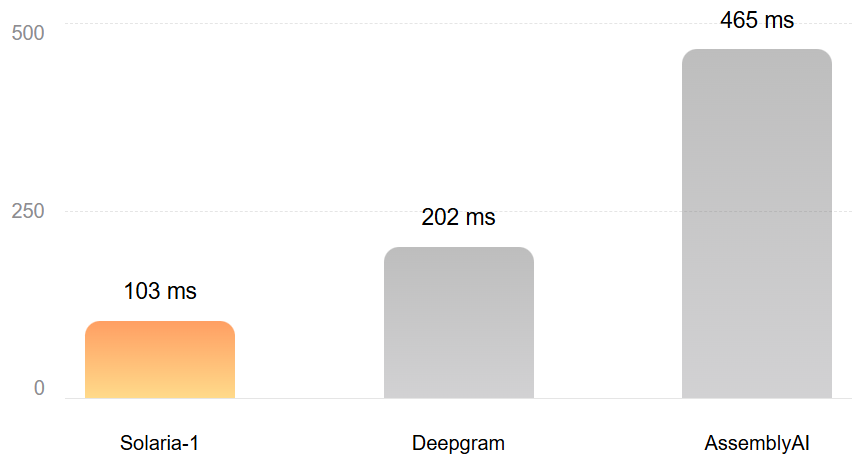
The Universal-Streaming model provides transcripts with sub-second latency (approximately 300 milliseconds at the median), suitable for applications like voice agents and live captioning.
The latest Universal-Streaming model features "immutable transcripts," meaning words that have already been produced will not be changed in subsequent messages. This provides more predictable output for real-time applications.
The system also includes intelligent endpointing to detect when speakers finish their turns, custom vocabulary for domain-specific terms, and session-based pricing where billing is based on total connection time.
Pricing: pay-as-you-go with modular add-ons
AssemblyAI uses a usage-based pricing model with no upfront commitments. The platform offers separate pricing for pre-recorded (asynchronous) and real-time (streaming) transcription, along with optional add-ons for Audio Intelligence features. AssemblyAI also offers multiple speech models at different price points, so cost depends on which model and features are selected. Here's an overview of how the pricing breaks down:
Speech-to-Text Models:
Universal-3 Pro (default, 6 languages): $0.21 per hour
Universal-2 (99 languages): $0.15 per hour
Universal-Streaming: $0.15 per hour
Universal-Streaming Multilingual (6 languages): $0.15 per hour
Add-ons (applicable to both modes):
Speaker Diarization: $0.02 per hour
Sentiment Analysis: $0.02 per hour
Entity Detection: $0.08 per hour
Summarization: $0.03 per hour
Topic Detection: $0.15 per hour
These add-ons stack on top of the base transcription rate. For example, using Universal-2 ($0.15/hr) with speaker diarization, sentiment analysis, entity detection, and summarization brings the effective rate to $0.30/hr. Adding topic detection increases it further to $0.45/hr.
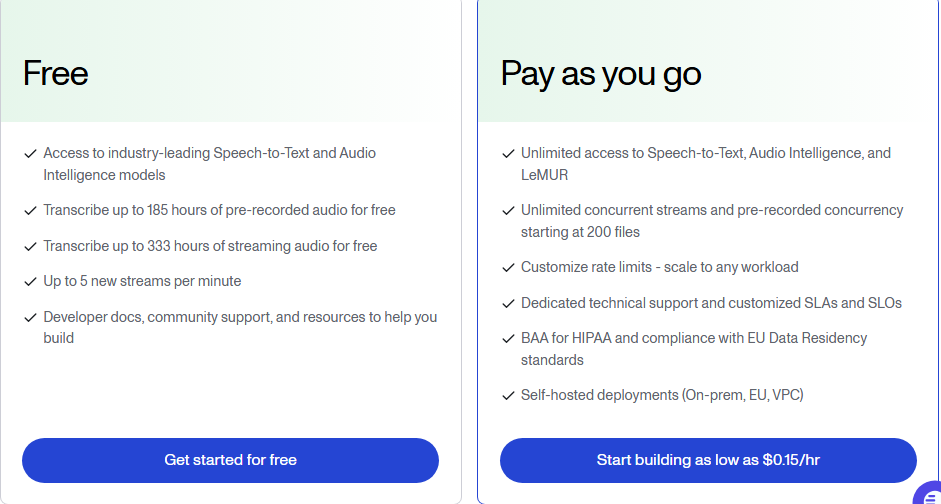
New users receive $50 in credits, providing approximately 185 hours of pre-recorded transcription or 333 hours of streaming. This is a one-time allocation rather than a recurring monthly tier. The free tier limits new streams to 5 per minute, with paid accounts starting at 100 new streams per minute.
While AssemblyAI provides a comprehensive suite of voice AI capabilities, several limitations become apparent for certain use cases. These constraints reflect the platform's optimization for depth in specific areas rather than breadth across all scenarios.
Multilingual Streaming Limitations: The real-time streaming API supports significantly fewer languages than the asynchronous transcription.
While pre-recorded audio can be transcribed in 99 languages, real-time streaming is limited to six major languages (English, Spanish, French, German, Italian, and Portuguese). For businesses operating globally with live audio streams in diverse languages, this creates a gap between what's possible with pre-recorded content and what's available in real-time.
Some users have also reported that language detection can produce inconsistent results, with transcription artifacts occasionally appearing when working with similar languages.
Expanding Platform Scope: AssemblyAI has been expanding beyond core speech-to-text into broader voice AI capabilities, including LLM integration through LeMUR and the LLM Gateway.
While this provides more functionality, it represents a shift toward becoming an end-to-end voice AI platform. For companies building their own voice agents or conversational AI products, this trajectory could eventually create competitive overlap; your infrastructure provider may offer solutions that compete with what you're building.
Data Privacy Considerations: AssemblyAI enrolls customers in its model improvement program by default.
Users can opt out, but this requires an explicit request, and free-tier users cannot opt out at all. The published pricing is offered subject to participation in this program, suggesting rates may differ for those who opt out. For organizations with strict data governance requirements, this default stance may require additional configuration and verification.
Pricing Complexity: The modular pricing structure, while flexible, can become complex to predict.
Each Audio Intelligence feature adds incremental costs, and combining multiple features for a single hour of audio can result in rates significantly higher than the base transcription price. For teams that need diarization, sentiment analysis, and summarization together, the total cost per hour can add up quickly.
One-Time Free Credits: Unlike some competitors that offer recurring monthly free tiers, AssemblyAI provides a one-time $50 credit allocation. Once exhausted, users must move to paid usage.
These limitations reflect AssemblyAI's focus on building deep capabilities in audio intelligence and LLM integration. However, they create opportunities for platforms that prioritize broader multilingual real-time support, simpler pricing structures, and a more focused approach to the speech-to-text layer.
Top AssemblyAI alternative: Gladia
Gladia addresses several of AssemblyAI's limitations through a different strategic approach: staying focused as a pure-play speech AI provider while delivering multilingual-first transcription and audio intelligence.
The platform emerged from Queguiner's frustration that existing transcription services couldn't accurately understand his French accent, a challenge that shaped Gladia's multilingual DNA from the start. Queguiner previously served as VP of AI at OVH, Europe's largest cloud provider.
Pure-play speech AI: a partner that won't compete
One of Gladia's defining characteristics is its commitment to remaining a vertical specialist in speech-to-text and audio intelligence.
While competitors are expanding into end-to-end voice AI solutions, adding LLMs, text-to-speech, and complete conversational AI products, Gladia deliberately stays focused on the "input side" of the voice stack.
This matters for companies building voice agents, AI assistants, or any product that combines speech-to-text with other AI components. When your STT provider also offers complete voice AI solutions, there's inherent competitive tension.
Gladia's pure-player positioning means they function as infrastructure partners rather than potential competitors, a distinction that can influence vendor decisions for teams building differentiated voice products.
Solaria-1 model: multilingual architecture from the ground up
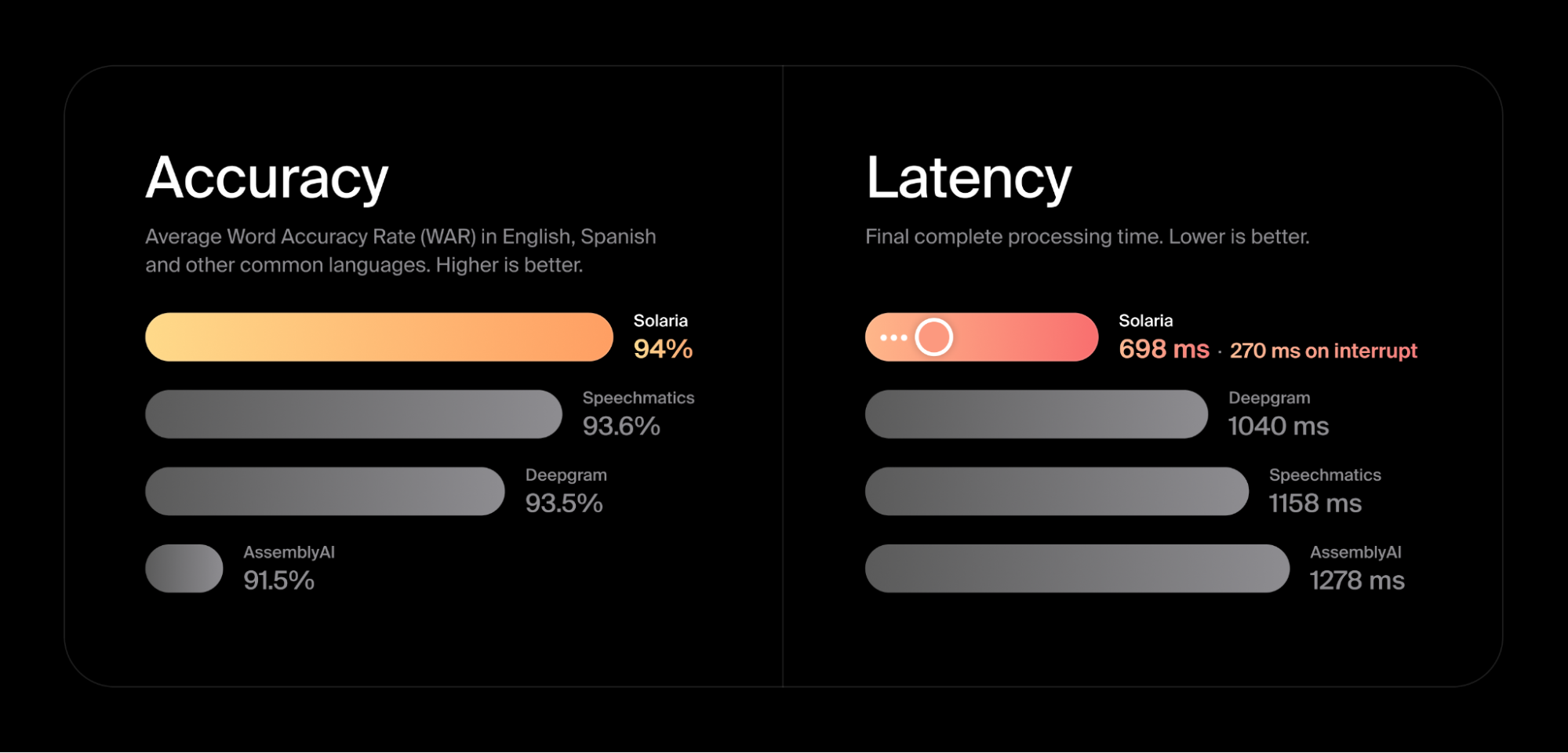
Gladia's latest Solaria-1 model delivers transcription in over 100 languages, with this extensive support available for both real-time streaming and pre-recorded audio.
According to Gladia's benchmarks using public datasets like Mozilla Common Voice and Google FLEURS, Solaria-1 achieves a 94% word accuracy rate in English, Spanish, French, and other common languages.
The platform's standout capability is code-switching: the ability to accurately transcribe conversations where speakers alternate between multiple languages naturally.
The system can automatically detect languages being spoken and annotate results accordingly, making it suited for international customer support, multilingual meetings, and global voice agent deployments.
Solaria-1 also includes 42 languages that Gladia reports are unsupported by competitors, including high-population markets like Bengali, Punjabi, Tamil, and Urdu, as well as regional languages common in call center outsourcing hubs.
The platform uses WebSocket connections for continuous bidirectional communication and employs Voice Activity Detection to intelligently identify speech segments.
The system provides both partial and final transcripts: partials offer immediate feedback as speech occurs, while finals provide higher accuracy once sufficient context is available. This latency profile is designed for what Gladia describes as "human-like" responsiveness, enabling natural, uninterrupted conversational interactions for voice agents and live captioning.
Precision beyond general accuracy
Beyond overall transcription accuracy (measured by word error rate), Gladia emphasizes precision for specific entities that matter in business contexts.
The platform includes named entity recognition that automatically detects email addresses, phone numbers, names, and alphanumeric sequences, entities that generic ASR engines often struggle with.
Custom vocabulary allows users to prompt the model with specific terminology, including per-term weighting and per-language configuration. This makes Gladia suited for specialized domains like medical transcription, financial services, and legal applications where getting specific terms right is critical.
Users can translate transcripts into multiple target languages in a single API call. The platform offers two translation models: a "base" model for fast translations suitable for most use cases, and an "enhanced" model providing higher quality, context-aware translations.
Translation options include settings for lip-syncing (useful for dubbed content) and context adaptation for improving translation of specific terminology. This consolidates transcription and translation into a single vendor relationship rather than requiring separate integrations.
Data privacy approach
Gladia takes a clear stance on data privacy.
According to their security documentation, Pro and Enterprise customers' data is not used for model training; only Free plan users are subject to this. This contrasts with providers that require customers to actively opt out or pay more for data exclusion.
The platform maintains zero data retention for customers, meaning no customer audio or transcripts are stored after processing. Data is used only to generate results and is then immediately deleted. This is particularly important for regulated industries handling sensitive data.
Data from EU and US workloads are kept separate on region-specific infrastructure. Gladia is SOC 2 Type 2 certified, HIPAA compliant, and GDPR compliant.
Audio intelligence included
Gladia provides audio intelligence features through the same API, with these capabilities included in the base pricing rather than charged as separate add-ons:
Speaker Diarization identifies different speakers with support for mono, stereo, and multi-channel audio. Users can provide hints about the expected number of speakers.
Summarization generates summaries in three types: general (balanced overview), concise (quick snapshot), and bullet points (key takeaways and action items).
Sentiment Analysis detects emotional tone at the sentence level, classifying sentiment as positive, neutral, negative, mixed, or unknown, and identifying specific emotions.
Named Entity Recognition identifies people, organizations, locations, dates, email addresses, and other entities within the transcript.
This bundled approach allows teams to move from basic transcription to comprehensive audio intelligence without additional procurement or pricing negotiations.
As a growth-stage company, Gladia emphasizes personalized support, assigning technical teams to work directly with customers in ways that larger providers typically cannot match. This hands-on approach has been cited by users switching from larger platforms as a differentiating factor.
Pricing: transparent and all-inclusive
Gladia's pricing follows a transparent, all-inclusive model where audio intelligence features are bundled into the base rate rather than charged separately. The platform offers different rates for real-time and asynchronous transcription, with volume discounts available at higher tiers.
Real-Time (Streaming) Transcription:
Self-Serve tier: from $0.75 per hour
Scaling tier: from $0.55 per hour
Asynchronous (Pre-recorded) Transcription:
Self-Serve tier: from $0.61 per hour
Scaling tier: from $0.50 per hour
All audio intelligence features, including speaker diarization, sentiment analysis, summarization, and named entity recognition, are included at these rates rather than priced as separate add-ons. This makes cost prediction straightforward: you pay one rate for transcription with full audio intelligence capabilities.
The free tier provides 10 hours of transcription per month, renewed monthly. This recurring allocation contrasts with one-time credit models, allowing ongoing experimentation and development.
Enterprise plans offer custom pricing with unlimited concurrent streams, dedicated support, and zero data retention.
¹ AssemblyAI base rate of $0.15/hr (Universal-2) plus speaker diarization ($0.02), sentiment analysis ($0.02), entity detection ($0.08), and summarization ($0.03). Adding topic detection ($0.15/hr) brings the total to $0.45/hr. Gladia's rate includes all audio intelligence features with no additional charges.
Final verdict
The choice between AssemblyAI and Gladia depends on your specific requirements, technical priorities, and strategic considerations.
Choose AssemblyAI if you're building applications that require advanced analysis of audio content, particularly if you want to leverage Large Language Models on speech data.
The LeMUR framework's ability to process up to 10 hours of audio with LLM-powered analysis is a distinctive capability. AssemblyAI excels when you need deep Audio Intelligence capabilities like content moderation, topic detection, and entity extraction, and when you prefer modular pricing that lets you pay only for specific features you use.
The platform's maturity, extensive documentation, and enterprise compliance certifications make it a solid choice for organizations that prioritize an established ecosystem and are comfortable with a provider that's expanding into broader voice AI solutions.
Choose Gladia if your applications involve multilingual audio, particularly beyond the six languages AssemblyAI supports for streaming, or if code-switching conversations are central to your use case.
Gladia's Solaria-1 model handles over 100 languages in real-time with competitive latency, making it suited for global customer support, international meetings, and voice agents serving diverse populations.
Beyond technical capabilities, Gladia's pure-play positioning matters if you're building voice agents or conversational AI products and want an infrastructure partner that won't expand into competing solutions. The region-specific data infrastructure for EU and US workloads, transparent all-inclusive pricing, and recurring free tier make it a natural fit for organizations that want predictable costs, GDPR compliance built in, and a vendor relationship focused on the transcription and audio intelligence layer.
Both platforms serve developers and enterprises well within their respective strengths.
AssemblyAI offers depth through its LLM integration and comprehensive Audio Intelligence suite at a lower base price point, though total costs increase with add-ons. Gladia offers breadth through its multilingual real-time capabilities and simplicity through its all-inclusive pricing, plus strategic alignment as a focused infrastructure partner.
Your choice should align with whether your priority is advanced audio analysis with modular pricing, or global real-time and async performance with transparent costs and a provider committed to staying in its lane.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
What is PII redaction?
Speech-To-Text
AssemblyAI Review 2026: Features, Pricing & Alternative
Speech-To-Text
Deepgram vs Gladia: Best Speech-to-Text API Compared [2026]
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.