Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
ElevenLabs vs Gladia: speech-to-text comparison for voice AI builders
ElevenLabs vs Gladia comparison for voice AI builders. Compare STT accuracy, latency, pricing, and features for production agents. Get real-world accuracy metrics, total cost models, and technical specs to evaluate whether unified vendor stack or best-of-breed STT fits your pipeline.
Meeting bot speech recognition requires sub-300ms STT latency, real-time diarization, and code-switching for reliable transcripts. Production meeting bots fail when transcription infrastructure cannot handle multi-speaker overlap, language switching, and speaker attribution in real time.
Meeting transcription common mistakes: what meeting assistant builders get wrong
Meeting transcription mistakes that break production systems: crosstalk handling, diarization failures, and code switching issues. Learn how to architect STT pipelines that survive real world audio conditions, avoid silent WebSocket failures, and prevent cost model surprises at scale.
One of the biggest challenges in building Voice AI Agents is response time—users expect natural, real-time conversations, but every millisecond counts. That’s why we’re thrilled to announce the general availability of partials on Gladia’s real-time API, a feature now open to all developers.
After an early access phase working closely with Voice AI builders, we’ve validated what many had been asking for: the ability to stream partial transcripts word by word, rather than waiting for the final output. By acting on these partials, agents can understand intent faster, interrupt at the right moment, and deliver a smoother, more responsive user experience.
With Gladia's partials, the first few words in an utterance are emitted exceptionally fast (<100ms, up to 2x faster than other providers offering partial transcripts), allowing voice agents to achieve industry-leading ultra-low latency.
In this blog, we dive into how partials work, how we tailored them to Voice AI agent flows, and how you can leverage partial transcripts together with LLMs to improve latency while ensuring fast, fluid, and natural customer-agent interactions.
What are partials and why they matter
Partials (short for “partial transcripts”) provide a word-by-word streaming transcription of spoken words as they are received. While partials are subject to change until the final transcription is complete, they deliver immediate, actionable insights.
For Voice AI platforms, this is a game-changer: even if partials are less accurate than finals, they can be sent to the LLM instantly, allowing the agent to begin formulating a response without delay. The result is a smoother, more natural call experience—a must-have for building truly fluid voice interactions.
Gladia’s partials tailored for Voice AI Agents
Our team carefully crafted the partials specifically for Voice AI Agent use cases. This means they are designed for ultra-low latency on the initial words of an utterance, with a regular pace for the remainder.
TTS (Text-to-Speech): Converts the answer back into voice (e.g., Cartesia, ElevenLabs).
The total time taken for this entire process, starting from audio input and speech-to-text, significantly impacts the overall quality of the call.
That's where partials come in.
For an AI agent, knowing when a user begins to speak and what they are saying is crucial; the regular speech_start event is often insufficient. The first few words of an utterance carry vital information:
Interruption: Signifies that the user has started speaking.
Intention: Reveals what the user is trying to communicate.
Consider these examples:
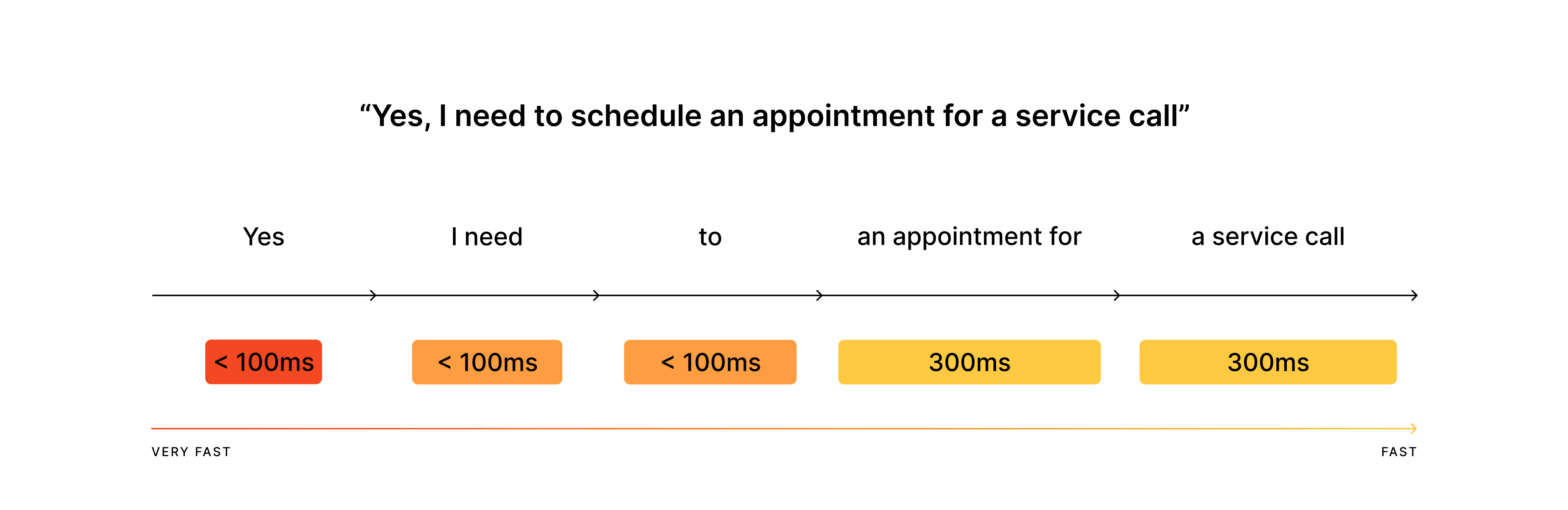
“Yes, I want to order…”
“Stop, this is not what I said…”
In both scenarios, the first word alone is often enough to understand the user's intent and to stop the AI from continuing to speak unnecessarily.
This is why, with our partials:
The first words are emitted exceptionally fast.
The rest of the utterance, until the final transcription, is emitted at a regular pace. This results in the following processing schema:
By enabling partials, voice agent flows can achieve ultra-low latency in the STT phase. Moreover, some of the time saved can be reallocated to utilize a more sophisticated LLM for crafting answers or to simply reduce the total response time, enhancing the user experience.
Partials + LLMs: picking the right configuration for optimal performance
To achieve superior latency for partials, our real-time API utilizes a smaller model than the one used for final transcriptions. In this context, "smaller" directly translates to "faster," requiring fewer milliseconds for inference.
While finals rely on "endpointing" to determine if an utterance is complete, partials are more time-based, with words being forced to be emitted as they are processed.
A significant advantage is that Large Language Models are adept at understanding imperfect or incomplete sentences. This means that the slightly lower accuracy of partials compared to finals is not a major impediment. LLMs can still effectively grasp the user's intent and generate appropriate responses.
For optimal results, we recommend explicitly selecting the target language from the language_config as opposed to having the model auto-detect it, as the minimal audio context makes language detection more sensitive.
Experiment with partials today!
The new developer playground now returns partials, allowing you to experience this feature firsthand.
Partials are live on all Gladia accounts. Please note that the real-time API does not return them by default. To enable this feature, simply use the messages_config.receive_partial_transcripts option when making your request.
For a quick start, refer to our comprehensive code samples, with TypeScript or Python snippets.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
ElevenLabs vs Gladia STT API Comparison 2026
Speech-To-Text
Meeting Bot Speech Recognition: STT API Guide 2026
Speech-To-Text
Meeting Transcription API Mistakes to Avoid in 2026
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


.png)
.png)
.png)