Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Call center transcription software: what enterprises should look for in 2026
TL;DR: Most contact centers evaluate transcription software using clean-audio lab benchmarks, then watch QA automation break down when BPO (Business Process Outsourcing) agents switch languages mid-call or phone-line noise degrades the signal. In 2026, the criteria that matter are real-world multilingual WER, all-inclusive per-hour pricing, and data sovereignty that holds up under GDPR and HIPAA audit. For enterprise teams, the highest-ROI evaluation step is testing on real BPO call samples rather than vendor demo audio, and asking every shortlisted provider for an all-in per-hour price with diarization, sentiment, and entity extraction enabled.
PII redaction for call recordings: how ingestion-level redaction keeps calls PCI compliant
TL;DR: Legacy pause-and-resume systems don't remove agents, local desktops, or telephony infrastructure from PCI DSS audit scope. Automated, ingestion-level PII redaction scrubs sensitive data before it reaches any database. By removing cardholder data at the ingestion layer, contact center platforms using automated redaction can potentially reduce audit complexity, cut agent handle time (AHT), and protect downstream CRM and LLM pipelines from corrupt data. The accuracy floor for reliable entity detection in PCI audits is significantly higher than for standard QA transcription, making STT model selection a compliance decision as much as a product one.
GDPR, SOC 2, and ISO 27001 speech-to-text: the contact center compliance and certification guide
TL;DR: When your contact center routes voice data through a transcription vendor, every certification gap in that vendor's stack becomes your compliance liability. Voice recordings qualify as personal data under GDPR Article 4, and processing them through uncertified APIs creates direct financial exposure. This guide breaks down what GDPR, SOC 2 Type II, ISO 27001, HIPAA, and PCI DSS each require of your audio infrastructure vendor and maps those requirements to the QA coverage rates and cost-per-contact metrics you manage daily. We hold GDPR, SOC 2 Type II, ISO 27001, HIPAA, and PCI DSS certifications, and never use customer audio for model training on Growth or Enterprise plan.
What is Word Error Rate (WER): How it’s calculated, and why it can mislead
Published on March 23, 2026
By Ani Ghazaryan
Word Error Rate (WER) is a metric that evaluates the performance of ASR systems by analyzing the accuracy of speech-to-text results. WER metric allows developers, scientists, and researchers to assess ASR performance. A lower WER indicates better ASR performance, and vice versa. The assessment allows for optimizing the ASR technologies over time and helps to compare speech-to-text models and providers for commercial use.
If you’re building anything with speech—meeting bots, voice assistants, call analytics—WER is the number you’re told to trust. Lower WER equals a better model. At least, that’s the assumption. In practice, it’s not that simple. The same model can report 5% WER in a benchmark and 25%+ in production, depending on audio quality, speakers, and evaluation setup. Worse, two providers can report similar WER while behaving very differently on your actual use case. WER isn’t wrong, but it’s incomplete without context, and often misinterpreted.
In this guide, we’ll break down what WER actually measures and how it’s calculated, but more importantly, how it behaves in practice. We’ll look at the evaluation pipeline behind it, the factors that cause scores to shift, and why results that look strong in benchmarks often don’t translate to production.
TL;DR:
Word Error Rate (WER) is the standard way to measure speech-to-text accuracy, but it only tells part of the story.
In practice, WER is highly sensitive to how evaluation is set up: the dataset, normalization rules, and scoring pipeline can all shift the result significantly.
To interpret WER correctly, it has to be tied to a reproducible evaluation setup and tested on data that reflects your actual use case.
Without that, it’s just a number useful for comparison, but not enough to judge real-world performance.
What is word error rate (WER)?
Automatic speech recognition systems convert spoken language into written text. They are used across a wide range of applications, including transcription, voice assistants, meeting summarization, and contact center analytics.
Historically, ASR systems were built as multi-stage pipelines, combining feature extraction, acoustic modeling, and language modeling as separate components. That architecture has largely been replaced by end-to-end neural systems. Modern models rely on large-scale pre-training and learn to map audio directly to text, often across multiple languages and domains. These systems are more flexible and more accurate than earlier approaches, but they are also more sensitive to evaluation conditions. Because they are trained on large and diverse datasets, their behavior varies significantly depending on input characteristics. This variability makes evaluation both more important and more complex.
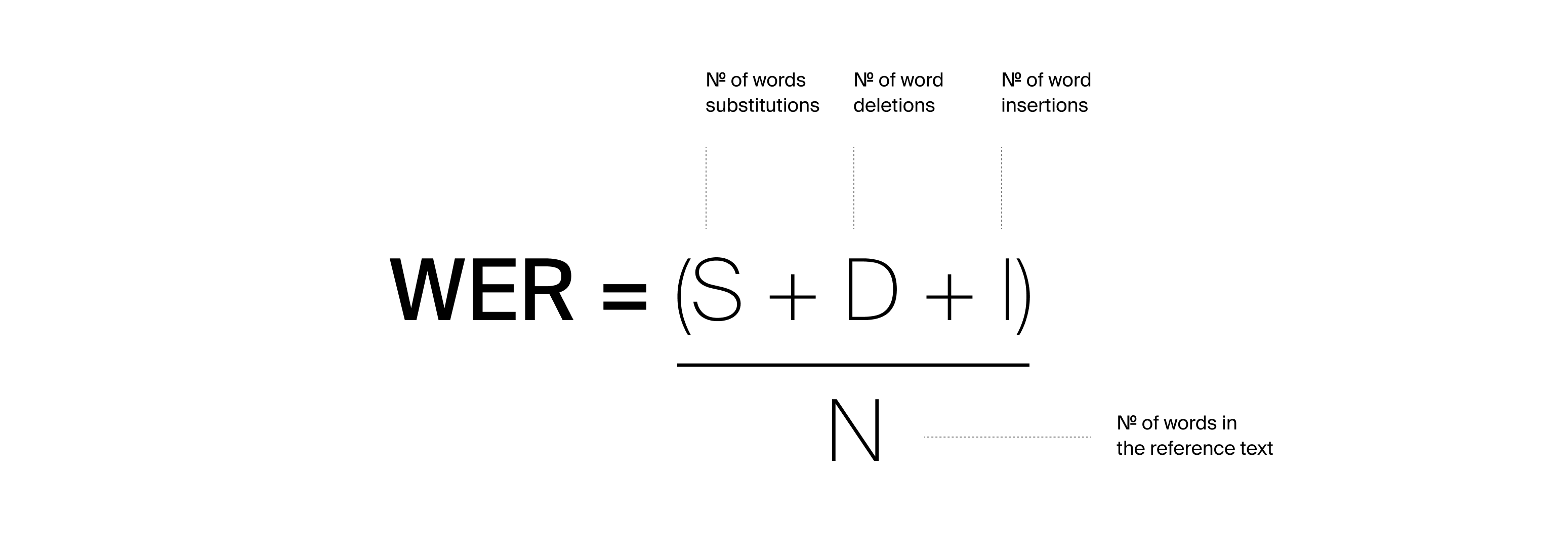
WER attempts to provide a standardized way to measure transcription accuracy by comparing a model’s output to a reference transcript. It counts how many edits are needed to transform the predicted text into the reference text. These edits fall into three categories: substitutions, deletions, and insertions.
Mathematical formula
Where S represents substitutions, D deletions, I insertions, and N the total number of words in the reference. This formulation is straightforward and has remained unchanged for decades. The complexity arises not from the formula itself, but from how the inputs to that formula are prepared.
When WER works and when it doesn’t
In controlled settings, WER is a useful metric. It provides a clear, quantitative way to compare systems and track improvements over time. If two models are evaluated on the same dataset, with identical preprocessing and scoring, WER can reliably indicate which one produces fewer transcription errors. However, this reliability depends on a critical assumption: that the evaluation setup is consistent and representative. In practice, this assumption rarely holds.
Consider a simple example. A user says, “Call me at five five five zero one nine nine.” One system outputs “Call me at 5550199.” Another outputs the words as spoken. Depending on how numbers are normalized, one system may appear significantly more accurate than the other, even though both outputs are equally usable. This highlights a fundamental limitation: WER measures string differences, not meaning or usability. It treats all errors equally, regardless of their impact. A minor formatting difference is penalized in the same way as a critical semantic error.
In production systems, this mismatch becomes more pronounced. A transcript with a slightly higher WER may still be more useful if it preserves key information correctly. Conversely, a transcript with low WER may contain errors that break downstream applications.
WER as an output of a pipeline
WER is often presented as a single, objective score. In reality, it’s the result of a multi-step evaluation pipeline, and each step introduces assumptions that shape the final number. Before scoring even begins, transcripts are typically normalized. This preprocessing step can include:
Lowercasing text
Removing punctuation
Expanding abbreviations
Standardizing numbers and dates
These transformations may seem minor, but they can significantly change the computed WER. A model can appear more or less accurate depending on how aggressively normalization is applied.
Next comes alignment: the process of matching predicted words to reference words. This is not a trivial step. Insertions, deletions, and substitutions create ambiguity, and different alignment algorithms can produce different error counts for the same pair of transcripts.
Tokenization adds another layer of variability. Languages differ in how words are segmented, and decisions about token boundaries directly affect how errors are counted. This becomes especially important in multilingual settings or in languages with more complex morphology.
Because of these dependencies, WER is not inherently reproducible. Two teams evaluating the same model can report different WER values if their pipelines differ. Without full transparency into preprocessing, alignment, and scoring, comparisons become unreliable. In practice, a WER score is the output of a sequence of transformations rather than a direct property of the model itself. A typical evaluation pipeline looks like this:
Audio → ASR model → raw transcript→ text normalization → tokenization → alignment (Levenshtein) → error counting → WER
Because of this, WER is only meaningful when the entire pipeline is fixed and reproducible. Changing any component can change the score without changing the underlying model.
Factors that influence WER in practice
WER is often interpreted as a measure of model quality, but in practice, observed scores reflect both the model and the conditions under which it’s evaluated.
Training data plays a central role: Public datasets such as LibriSpeech or Common Voice are commonly used for benchmarking, but they represent only a narrow slice of real-world speech. They tend to consist of clean, read audio with limited variability. Models that perform well on these datasets may struggle when exposed to conversational or domain-specific speech.
Acoustic conditions introduce another layer of variability: Background noise, microphone quality, and compression artifacts all degrade signal quality and increase error rates. A model evaluated on studio-quality recordings may appear highly accurate, but its performance can drop significantly in environments such as call centers or mobile recordings.
Speaker variability further complicates evaluation: Differences in accent, speaking rate, and pronunciation affect recognition accuracy. In conversational settings, additional challenges arise from interruptions, overlapping speech, and incomplete sentences. These characteristics are difficult to capture in standard benchmarks.
Language itself adds complexity: Multilingual speech, code-switching, and domain-specific vocabulary all increase the difficulty of transcription. For example, a sentence that mixes languages within the same utterance may not align well with the assumptions of models trained on monolingual data.
These factors interact in non-trivial ways. A model that performs well in one domain may perform poorly in another, even if the overall WER appears competitive. This variability is one of the main reasons why benchmark results often fail to generalize.
Why benchmarking ASR systems is inherently difficult
Benchmarking attempts to provide a controlled environment for comparison, but it introduces its own limitations.
One challenge lies in the definition of ground truth: Reference transcripts are not always consistent. Differences in formatting, punctuation, or normalization can lead to different WER values. In some cases, ground truth data may contain errors, particularly in large or weakly supervised datasets.
Another issue is dataset representativeness: Benchmark datasets are often curated for research purposes and do not reflect production environments. They may exclude noisy audio, multi-speaker interactions, or domain-specific language. As a result, they provide an incomplete picture of system performance.
Benchmark design also introduces bias: Choices about which data to include, how to preprocess it, and how to score results all affect the outcome. Even small differences in normalization or filtering can produce noticeable changes in WER.
A more subtle issue is the lack of standardization: There is no universally accepted evaluation pipeline for ASR. Different organizations use different normalization rules, alignment strategies, and scoring implementations. This lack of consistency makes it difficult to compare results across systems.
Finally, benchmarking is resource-intensive. Building high-quality evaluation datasets and pipelines requires time, expertise, and infrastructure. Many teams rely on vendor-reported metrics as a result, even when those metrics are not fully transparent.
What WER looks like in a reproducible benchmark
To understand how WER behaves in practice, it helps to look at results from a controlled, reproducible evaluation setup.
In Gladia’s recent speech-to-text benchmarks, multiple leading STT APIs were evaluated under identical conditions across diverse datasets, including clean speech, multilingual audio, and long-form conversational recordings. The results highlight a key reality: WER is not a single number—it shifts significantly depending on context.
On clean datasets like Common Voice, top systems achieve WER in the ~3–7% range
On structured but real-world speech (e.g. VoxPopuli), WER drops further (~1.7–3.2%) due to cleaner references
On long-form, domain-specific audio (Earnings calls), WER increases to ~9–14%
On conversational speech (e.g. Switchboard), error rates can exceed 35–60%, driven by interruptions, disfluencies, and speaker variability
This variation is not an anomaly. It is the expected behavior of modern ASR systems. Even when models are evaluated with the same pipeline, no single provider consistently outperforms others across all datasets. Performance depends on how well a system handles specific conditions: noise, speaker overlap, language switching, and domain vocabulary.
This reinforces a practical reality: a single WER number, in isolation, says very little about real-world performance.
How WER behaves across real-world scenarios
ASR performance holds up well on clean, read speech, but starts to break down as conditions become more realistic. In conversational audio, people interrupt each other, speak in fragments, and vary their phrasing; add background noise, and the signal itself becomes harder to interpret. Multilingual and code-switching scenarios push models further, requiring them to switch between languages mid-sentence—something rarely reflected in standard benchmarks. Lower-quality audio introduces even more issues, from hallucinated words to repeated or missing segments, many of which aren’t fully captured by WER. On top of that, domain-specific vocabulary often leads to consistent errors, with a disproportionate impact on downstream tasks.
Beyond WER: evaluating what actually matters
WER is a useful baseline. But in production, it’s rarely what breaks your system. What matters isn’t whether a transcript is globally accurate. It’s whether it’s functionally correct for your use case. A single error in a phone number, a date, or a proper name can break an entire workflow, even if the rest of the transcript is flawless. WER treats that the same as a missing “the” or a punctuation difference. From a system perspective, those errors are not equal.
The same applies to meaning. A transcript that swaps “Tuesday” for “Thursday” may still score well on WER, but it’s objectively wrong. And in many applications, that’s a critical failure. This is why evaluation is shifting. Teams are moving beyond generic accuracy metrics toward measurements that reflect real usage: entity accuracy, character-level precision, and, increasingly, task-level outcomes like search relevance or data extraction quality. The question is no longer “How close is this to the reference?” It’s “Does this transcript actually work?”
The only way to answer that is to test models on real audio, not just benchmarks. That’s exactly what Gladia is built for: try it on your data and evaluate what actually matters.
FAQ
What is a good WER? There is no universal threshold because WER depends heavily on audio conditions and use case. For clean, read speech, a WER below 10% is typically considered strong, while in noisy, conversational, or multi-speaker settings, 15–30% may still be acceptable. The key is to evaluate WER relative to your domain, not in isolation.
Is lower WER always better? Not necessarily. WER measures surface-level differences, not meaning, so a lower score does not guarantee that the transcript is more useful. In many applications, preserving critical information such as names, numbers, or intent matters more than minimizing total word errors.
Why does WER vary between providers? WER varies because providers often use different datasets, normalization rules, and evaluation pipelines. Even small differences in preprocessing or scoring can lead to significantly different results. Without a shared evaluation setup, WER comparisons are not directly comparable.
Can two systems have the same WER but different quality? Yes. Two transcripts can have identical WER while differing in semantic accuracy or usefulness. For example, one may preserve key entities correctly while the other introduces critical errors that affect downstream tasks.
Should vendor benchmarks be trusted? Vendor benchmarks can provide a directional signal, but they should be interpreted cautiously. They are only meaningful if the methodology, datasets, and evaluation pipeline are fully transparent and reproducible. The most reliable approach is to test systems on your own data under controlled conditions.
Glossary
ASR (Automatic Speech Recognition): Technology that converts spoken language into text, typically using end-to-end neural models trained on large-scale audio data.
WER (Word Error Rate): A metric that measures transcription accuracy by counting substitutions, deletions, and insertions relative to a reference transcript.
Normalization: The process of standardizing text before evaluation, including handling numbers, punctuation, casing, and formatting to ensure consistent comparison.
Ground truth: The reference transcript used for evaluation, ideally accurate and consistently formatted, though in practice it may contain variability or errors.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Call center transcription software: what enterprises should look for in 2026
Speech-To-Text
PII redaction for call recordings: how ingestion-level redaction keeps calls PCI compliant
Speech-To-Text
GDPR, SOC 2, and ISO 27001 speech-to-text: the contact center compliance and certification guide
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.





















.png)