Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Call center voice analytics: use cases, benefits, and how it works
TL;DR: Contact centers that rely on manual QA for call review typically sample only a small fraction of their total call volume, leaving the vast majority of audio unanalyzed. Voice analytics fixes this by converting raw phone calls into structured, LLM-ready data that feeds QA scorecards, CRM entries, and coaching workflows automatically. The catch is that telephony audio is uniquely hostile to standard speech APIs because narrowband codecs and packet loss break models trained on clean audio. This article explains the technical pipeline, the metrics that matter, and the infrastructure requirements that separate production-ready systems from vendor demos.
Customer sentiment analysis: methods, tools, and what voice data adds
TL;DR: Reliable sentiment analysis requires WER below 5%, speaker diarization that separates customer and agent emotion, and language models that hold performance across accents and code-switching. Text-only sentiment tools miss critical voice signals (pace, talk-over, vocal intensity) that predict churn before survey data surfaces the same risk. Automated sentiment scoring on high-accuracy transcripts shifts QA from sampling 2–5% of calls to monitoring 100% of them, the only coverage level at which churn risk and agent burnout surface early enough to act on.
Named Entity Recognition from call transcripts: improving precision
TL;DR: Standard NER models trained on clean text lose up to 27 F1 points when applied to raw ASR output. For CCaaS operations running automated QA and CRM sync, that gap translates directly into missed account numbers, corrupted customer records, and unreliable coaching scores. The fix starts at the transcription layer. Our Solaria-1 model delivers lower WER on conversational speech and 3x lower DER than alternatives, giving your NER pipeline a clean text foundation before a single field is written to the CRM.
STT API benchmarks: How to measure accuracy, latency, and real-world performance
Published on March 24, 2026
Ani Ghazaryan
Benchmarking STT APIs in 2026 requires more than WER. Learn how to evaluate STT APIs using latency, diarization, and real-world conditions in 2026.
Every product that depends on voice input ultimately depends on how well its speech-to-text (STT) layer performs in production. And that’s exactly where most evaluations fall apart. On paper, a small benchmark delta can look negligible. In practice, it’s anything but. A few points of WER can translate into missed intents, broken downstream actions, incorrect speaker attribution, or summaries that read fluently but are factually wrong.
The issue is that vendors still report clean accuracy numbers on curated datasets. But production systems don’t fail on curated datasets. They fail on interruptions, overlapping speech, background noise, unstable partials, long-form drift, and language variability. That shift—from clean conditions to messy reality—is what makes benchmarking STT APIs in 2026 fundamentally different.
It’s no longer about comparing a single score. It’s about understanding where a system holds up, where it degrades, and which evaluation mode actually reflects your use case.
TL;DR:
WER is still useful, but incomplete without normalization and dataset context
Real-time and asynchronous STT require different evaluation approaches
Latency, diarization, and robustness to real-world audio now shape product quality as much as raw accuracy
Real-world, multi-domain benchmarks consistently expose gaps vs vendor claims
The only reliable evaluation is one that mirrors your production conditions
Why traditional STT benchmarks break in production
Most benchmark claims break down for a simple reason: they optimize for comparability, not realism. Clean benchmarks remove variability. They simplify speech into something models can process consistently—no overlap, stable audio quality, predictable structure. That makes ranking easier, but it also strips away the very conditions that matter in production. Real-world audio behaves differently. Speech is interrupted, corrected mid-sentence, overlapped by other speakers, or partially masked by noise. The system isn’t decoding a finished signal—it’s resolving ambiguity in real time. This is why performance shifts across datasets shouldn’t be dismissed as noise. They are signals.
When you evaluate across conversational, multilingual, long-form, and noisy audio, degradation is not only expected—it’s consistent. In our latest multi-domain benchmark this is visible across datasets like Switchboard (conversational telephone speech), Earnings22 (long-form financial audio), and noisy evaluation sets, where WER increases relative to cleaner corpora. That degradation isn’t a flaw. It’s a reflection of reality.
This is also where multi-domain benchmarks become valuable—not because they produce better numbers, but because they force evaluation across fundamentally different conditions instead of a single curated dataset. The deeper issue isn’t that traditional benchmarks are wrong. It’s that they answer a narrower question: “How well does this model perform under controlled conditions?” What production systems actually need is a different question: “How does this model behave when the input is unstable, incomplete, and noisy?”
Core metrics (and what they miss)
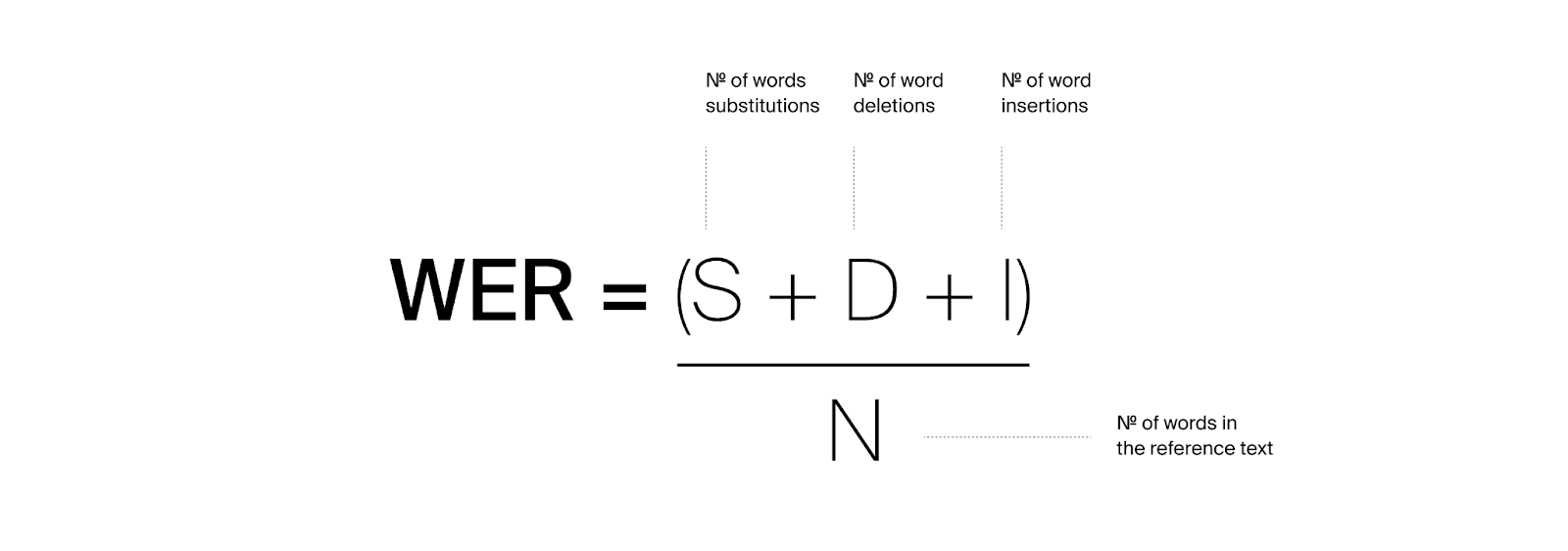
Word Error Rate (WER)
WER remains the default metric for speech-to-text accuracy and for good reason.
The lower the WER, the better the quality of the transcription. A perfect system would have a WER of 0%. In real life, what that translates to is:
A 5% WER is excellent / near human parity: 1 error in a 20-word sentence
A 10% WER is good / highly usable: 1 error in a 10-word sentence
A 20% WER is fair / needs manual review: 2 errors in a 10-word sentence
It’s standardized, widely understood, and easy to compare. But its usefulness drops quickly as soon as you move beyond clean benchmarks.
Two transcripts with identical WER can have very different impact. A single missed entity, number, or speaker attribution can matter far more than several minor substitutions. WER treats them the same. It’s also sensitive to formatting. Without normalization, differences like “$50” vs “fifty dollars” are counted as errors. This is one reason multi-domain asynchronous benchmarks tend to be more reliable—they combine normalization with dataset diversity, reducing noise in the metric. Even then, WER has a clear limitation: It tells you how often text differs. It doesn’t tell you whether the output is usable.
Latency and Real-Time Factor (RTFx)
If WER defines correctness, latency defines usability. In real-time systems, even highly accurate transcripts become useless if they arrive too late. Timing isn’t a secondary concern, it’s part of the product. RTFx measures processing speed relative to audio duration, but it doesn’t capture how streaming systems behave under continuous input. In practice, latency splits into two distinct measurements:
Time to First Byte (TTFB): how quickly the system starts returning text after audio begins
Latency to final: how long it takes to produce a stable, finalized transcript
These two often diverge. A system may respond quickly but take longer to stabilize, especially with longer or more complex audio. That’s why real-time usability depends on more than just speed:
how quickly the first tokens appear
how often partial transcripts change
how stable intermediate outputs are
This is exactly what real-time benchmarks are designed to capture. And importantly, streaming systems fail differently than batch systems. Whether you optimize for TTFB or latency to final directly shapes system behavior.
Diarization Error Rate (DER)
As soon as you introduce multiple speakers, diarization stops being optional. A transcript without reliable speaker attribution is structurally incomplete. In meetings, calls, and interviews, meaning depends on who said what. So, DER measures how often the system misses speech, hallucinates speech, and assigns speech to the wrong speaker.
What makes speaker diarization challenging isn’t the metric itself, but its sensitivity to context. Performance shifts significantly depending on overlap, noise, and conversational dynamics.
In our recent benchmark, diarization is evaluated across DIHARD III domains—meetings, broadcast, restaurant, and conversational telephone speech. The variation across these domains highlights how quickly speaker attribution breaks down in noisier or more interactive settings.
That’s why diarization is rarely evaluated in isolation. It behaves differently depending on the environment, and those differences matter in production.
Real-time vs asynchronous evaluation: when each matters
At this point, a key distinction becomes unavoidable. In 2026, STT systems operate in two fundamentally different modes: streaming and asynchronous. Evaluating them the same way can lead to misleading conclusions.
Real-time evaluation (streaming systems)
Streaming systems operate without full context. Every output is provisional. As a result, evaluation focuses on behavior over time:
how quickly usable text appears
how stable partial transcripts are
how the system balances speed vs revision
Benchmarks in this category typically use short, conversational audio to simulate live conditions. They’re most relevant for voice assistants, live captioning, and conversational AI. In these systems, users interact with the transcript as it’s being generated. Stability and latency matter just as much as correctness.
Asynchronous evaluation (batch systems)
Batch systems, by contrast, operate with full context. They can optimize for the final result. Evaluation therefore shifts toward final accuracy (WER), speaker diarization, robustness across domains, and long-form consistency.
This is where multi-dataset benchmarks become essential. By combining datasets like Switchboard, Multilingual LibriSpeech, Earnings22, and noisy audio collections, they provide a more realistic view of system behavior once audio is complete. These evaluations are most relevant for call analytics, meeting transcription, and indexing or search.
What modern benchmarks reveal (and vendor claims don’t)
Performance is conditional, not absolute
Performance no longer holds constant across domains. A model that performs well on clean or read speech often degrades on conversational audio, where overlap, disfluencies, and turn-taking introduce ambiguity. This becomes clear in multi-dataset evaluations, where results vary across datasets like Switchboard, Multilingual LibriSpeech, and Earnings22—each exposing a different failure mode. Models don’t fail uniformly. They fail along specific dimensions. A single score hides that.
Long-form audio exposes accumulation
Short clips reveal isolated mistakes. Long-form audio reveals behavior over time. Errors accumulate. Small inconsistencies in segmentation, punctuation, or speaker attribution compound across longer recordings. This is especially visible in datasets like earnings calls, where structure matters as much as accuracy. This is often where strong short-form performance starts to degrade.
Rankings break once conditions change
As soon as evaluation spans multiple datasets, rankings stop being stable. A model that leads on one dataset may drop significantly on another. This is exactly why multi-domain benchmarks matter. Not because they produce a definitive ranking, but because they show how rankings shift.
The failures that matter are at the edges
Average performance hides the cases that actually break systems. The most impactful failures tend to happen at the edges including overlapping speakers, sudden noise spikes, language switches, and segmentation breakdowns. Modern benchmarks explicitly include these conditions. And because of that, they align far more closely with production reality than benchmarks optimized for clean averages.
Real-world performance factors
All of this leads to a practical question: what actually drives performance in production? Clean audio helps isolate behavior. But real-world audio is rarely clean, and that’s where most systems begin to degrade.
In practice, performance is shaped by a mix of acoustic, linguistic, and conversational factors. These aren’t edge cases, they’re the default. If your evaluation doesn’t include them, it won’t predict production behavior.
Environmental noise and device variability
Production audio is often captured in imperfect conditions: speakerphones, low-quality microphones, background conversations, unstable input. These introduce overlapping speech, distortion, and intermittent noise—all of which impact transcription quality. Models trained on clean, close-talk audio tend to degrade significantly in far-field or noisy environments. That’s why modern benchmarks include noisy and multi-speaker datasets.
Language, accents, and code-switching
Language support is about consistency across speakers and contexts. In practice, many systems still perform unevenly across accents, dialects, and non-native speech. This becomes more visible in multilingual environments, where speakers may switch languages mid-sentence or mix linguistic patterns within the same utterance.
Code-switching and accent variation introduce ambiguity at both the acoustic and language modeling levels. Systems that are not designed for these conditions tend to degrade in ways that are not immediately visible in aggregate metrics like WER, but that impact downstream usability. This is one of the reasons multi-domain and multilingual evaluation is becoming standard: it exposes performance variability that single-language benchmarks tend to hide.
Speaker dynamics and conversational structure
Speech in production isn’t linear. People interrupt each other, self-correct, overlap, and shift topics mid-sentence. These dynamics affect more than recognition impacting segmentation, punctuation, and speaker attribution. Diarization becomes especially critical here. Because even when the words are mostly correct, incorrect speaker attribution can make transcripts difficult to interpret.
Bias, coverage, and model generalization
Performance differences across demographic groups remain a known issue. These differences often stem from imbalances in training data—across accent, age, gender, and speaking style. In practice, this shows up as uneven performance across user groups, particularly for less represented accents or speaking patterns. Modern evaluation increasingly focuses on performance slices rather than global averages—shifting the question from “how does the model perform overall?” to “where does it degrade, and for whom?”
Practical takeaways for evaluating STT APIs
Benchmarks are useful, but only as a first filter.
They help reduce the search space, not make the final decision. Once you’ve identified a few viable options, the evaluation needs to move closer to how your system will actually operate.
The first step is aligning the evaluation with your use case. Streaming and batch systems behave differently, and the metrics that matter in one don’t always translate to the other. If your product depends on real-time interaction, latency and partial transcript stability will define usability. If you’re working with recorded audio, final accuracy, structure, and consistency over longer segments become more important.
From there, the most important shift is introducing your own data. Even a small sample of real audio—reflecting your speakers, environments, and edge cases—will surface issues that benchmarks can’t fully capture. This is usually where differences between systems become obvious.
It’s also important to look beyond WER. Accuracy alone rarely determines whether a system is usable. Latency, diarization quality, and how the system behaves under difficult conditions often have a larger impact in practice. A slightly less accurate system that is more stable or better structured can be the better choice.
Finally, focus on where systems break. Average performance tends to smooth out the cases that actually cause problems in production. Overlap, noise, language switches, and long-form drift are not edge cases in practice—they’re common enough to define user experience.
The goal is not to find the highest score. It is to understand how a system behaves under your conditions, and reduce uncertainty before committing to it.
This is the same evaluation pipeline we used across 8 providers and 7 datasets, and 74+ hours of audio: transcription, normalization, and scoring applied consistently across all systems. Run it on your own data, and you’ll see where performance actually diverges. Even a small sample of real calls or meetings is enough to surface meaningful gaps, especially under noise, overlap, or long-form conditions. The full setup is open-sourced on GitHub.
FAQs
What is the most important metric for STT accuracy? WER is the standard, but it must be interpreted with normalization and realistic datasets. On its own, it is incomplete. In practice, WER should be read alongside context—dataset type, audio conditions, and whether errors affect meaning.
Why do benchmark scores differ from production results? Because benchmarks simplify audio conditions. Production introduces overlap, noise, and variability, which compound and expose different failure modes. As a result, models that perform similarly on clean datasets can diverge significantly once deployed.
How should I evaluate real-time transcription? Focus on latency, responsiveness, and partial transcript stability—not just final accuracy. Intermediate outputs matter because systems act on them before they are finalized. In practice, this means measuring how quickly usable text appears and how often it changes.
What is diarization and why does it matter? Diarization identifies speakers. Errors affect structure and meaning, especially in multi-speaker scenarios. In practice, poor diarization can make otherwise accurate transcripts difficult to use or interpret.
Can I rely on vendor benchmarks? They are useful for comparison, but should always be validated against your own data and use case. Differences in audio conditions, domains, and evaluation methods can significantly impact results.
Terminology
STT (Speech-to-Text): Converts spoken audio into text. It’s typically the entry point for downstream systems like search, analytics, or LLM-based processing. Its quality directly impacts everything built on top of it.
WER (Word Error Rate): Measures transcription accuracy based on substitutions, deletions, and insertions. Most useful when combined with normalization and realistic datasets. On its own, it does not capture whether errors affect meaning or usability.
Latency: Time between receiving audio and producing text. In real-time systems, even small delays affect usability. It is often split into time to first token and time to final transcript.
RTFx (Real-Time Factor): Compares processing speed to audio duration. Does not capture streaming stability or partial output behavior. It is more informative in batch contexts than in live systems.
Diarization: Identifies who is speaking in an audio stream. Critical for structuring conversations and enabling downstream reasoning. Its importance increases with speaker count and overlap.
DER (Diarization Error Rate): Measures how often speaker attribution is incorrect across different conditions. Performance can vary significantly depending on overlap, noise, and conversational dynamics.
Streaming / Real-time STT: Processes audio as it arrives. Optimized for responsiveness and partial output stability. Evaluation focuses on behavior over time, not just final output.
Asynchronous / Batch STT: Processes audio after completion. Optimized for final accuracy and consistency over longer recordings. Evaluation focuses on robustness across domains and long-form behavior.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Call center voice analytics: use cases, benefits, and how it works
Speech-To-Text
Customer sentiment analysis: methods, tools, and what voice data adds
Speech-To-Text
Named Entity Recognition from call transcripts: improving precision
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.