
7 Deepgram alternatives: Speech-to-text solutions for specific business needs
But as speech AI requirements become more specific, Deepgram's strengths may not perfectly align with every organization's priorities.
Perhaps the need is for broader language coverage for a global user base. Maybe the priority is a platform with specific data privacy configurations, or one that offers human transcription as a fallback for mission-critical content. Some teams need air-gapped deployment capabilities, while others want to reduce per-minute costs through self-hosting.
That's where this guide comes in. The Gladia team researched various Deepgram alternatives to identify platforms that excel in specific areas where organizations' needs might diverge from what Deepgram offers best.
This guide covers dedicated Deepgram alternatives that excel in specific areas:
This isn't about finding a "better" platform; it's about finding the right fit for specific requirements. Some teams might use these alternatives alongside Deepgram, while others might switch entirely. Read on to explore the options that can provide the specialized capabilities needed for different use cases.
Table of Contents

Deepgram is a foundational AI company specializing in voice technology, offering developers and enterprises a comprehensive speech-to-text platform built on end-to-end deep learning.
Founded in 2015 by former physicists, the company has raised over $215 million in funding and serves customers across contact centers, media, healthcare, and finance.
Its key features include:
Flexible Deployment: Cloud, on-premise, and dedicated single-tenant options
Deepgram's platform works by processing audio through its proprietary Nova models, which are trained on diverse datasets to handle various accents, background noise, and speaking styles. When audio is submitted via API, it flows through Deepgram's deep learning pipeline and returns structured JSON containing the transcript, timestamps, confidence scores, and any requested intelligence features.
The platform excels for teams building voice applications who value speed, accuracy, and the flexibility to customize models for their specific domain.
However, organizations with requirements beyond Deepgram's current offerings (such as broader language coverage, specific compliance configurations, or human transcription fallback) may find better fits among the alternatives explored below.
After testing Deepgram and researching the speech-to-text market, the focus was on finding platforms that excel in specific areas where organizations often need capabilities beyond what Deepgram currently prioritizes.
While Deepgram offers excellent performance for many use cases, businesses frequently need specialized solutions for:
Each platform on this list is a leader in one of these specific areas. Teams might use them alongside Deepgram for particular use cases, or switch entirely depending on requirements.

Gladia is an AI-powered audio intelligence platform built for developers and enterprises who need extensive multilingual support, real-time or async performance, and configurable data privacy controls. Founded in 2022 in Paris, Gladia has raised $20.3 million and serves over 600 enterprise customers, including Aircal Attention and Circleback.
Its key capabilities include:
Configurable Data Privacy:Automatic model training opt-out for paid tiers, with zero data retention available for enterprise customers
For organizations building global applications that serve multilingual user bases, Gladia provides capabilities that complement or extend beyond Deepgram's offerings.
The platform's code-switching feature is particularly valuable: when speakers alternate between languages mid-conversation (common in international business contexts), Gladia transcribes seamlessly without requiring manual language selection.
While Deepgram offers multilingual transcription with code-switching through Nova-3, Gladia provides broader language coverage and was purpose-built for extensive multilingual scenarios.
Gladia supports over 100 languages for transcription, more than double Deepgram's 40+ language coverage with Nova-3.
Gladia handles code-switching natively: when speakers alternate between languages within the same conversation, the system transcribes accurately without requiring language pre-selection or detection-triggered model swaps.
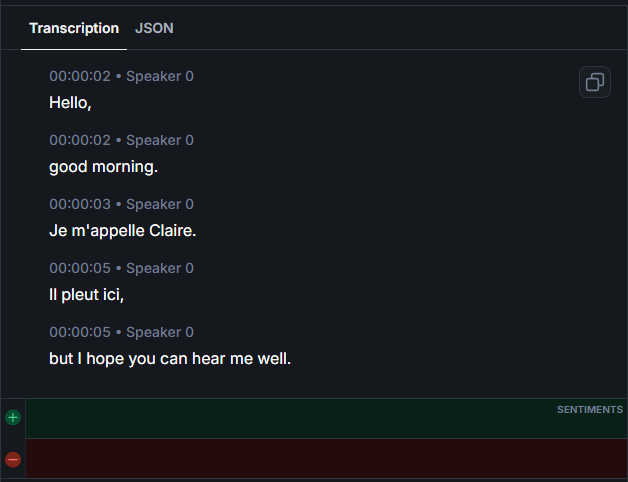
This capability addresses a real-world challenge in multinational enterprises, customer support centers, and diverse communities where conversations frequently mix languages.
Deepgram's Nova-3 also offers multilingual code-switching, but it is currently limited to 10 languages (English, Spanish, French, German, Hindi, Russian, Portuguese, Japanese, Italian, and Dutch). Gladia's code-switching spans the full 100+ language set in both real-time and async modes, making it particularly suited for global applications requiring less common language support.
⚡ Gladia in Action: Consider a customer support call where a bilingual agent switches between English and Spanish based on the customer's comfort level. With Gladia, the transcript captures both languages accurately in a single, continuous output. The system annotates results with language codes so downstream applications can process the conversation appropriately. No manual configuration required; the model handles language transitions automatically.
Gladia offers configurable data privacy controls that vary by subscription tier. For paid tier customers (Self-Serve, Scaling, and Enterprise), the company does not use customer audio to retrain models. Free tier users should note that their audio may be used for model improvement.
While Deepgram's privacy policy includes participation in a Model Improvement Program (with listed rates assuming opt-in), Gladia's paid tiers include automatic training opt-out. For enterprise and scaling tier customers, Gladia offers explicit model training exclusions, and enterprise customers can access zero data retention options.
⚡ Gladia in Action: A healthcare technology company processing patient consultations needs assurance that sensitive audio won't be used for model training. With Gladia's enterprise tier, they can configure zero data retention and receive explicit guarantees against data reuse. This simplifies compliance documentation and reduces the legal review burden when evaluating vendors.
Gladia provides a full suite of audio intelligence features through its unified API, including speaker diarization, sentiment analysis, summarization, named entity recognition, and custom vocabulary support. Deepgram also offers audio intelligence capabilities, giving teams options based on their specific feature needs.

Gladia's summarization feature offers three output formats (general, concise, and bullet points) powered by large language models. Sentiment analysis identifies emotional tone at the sentence level and can attribute sentiment to individual speakers when used with diarization. Named entity recognition automatically identifies and categorizes people, organizations, locations, dates, and more.
⚡ Gladia in Action: A sales enablement platform wants to analyze recorded sales calls to identify key topics, track sentiment shifts, and extract action items. With Gladia, a single API call returns the transcript with speaker labels, sentiment scores for each segment, a bullet-point summary of key takeaways, and extracted entities like company names and contact information. The development team doesn't need to orchestrate multiple services or build custom post-processing pipelines.
🏅 NOTE: We also evaluated Soniox for the multilingual category, which offers strong real-time translation capabilities. While Soniox excels at any-to-any translation between 60+ languages, Gladia provides broader transcription-first language coverage (100+). Both platforms offer comparable enterprise compliance certifications (GDPR, HIPAA, SOC 2 Type 2). For teams whose primary need is multilingual transcription with code-switching rather than real-time translation, Gladia offers more extensive language support.
Gladia offers usage-based pricing with separate rates for real-time and asynchronous transcription. All plans include bundled audio intelligence features like speaker diarization and sentiment analysis at no additional cost. Here's the breakdown by tier:
Self-Serve
Scaling (Contact sales)
Enterprise (Custom pricing)

Source: Gladia
Choose Gladia if:
Ready to transcribe in 100+ languages with native code-switching? Get started with Gladia's 10 free hours monthly and experience sub-300ms real-time performance with configurable privacy controls.
Get started with Gladia's 10 free hours monthly
AssemblyAI positions itself as a "Speech Understanding" platform rather than merely a transcription service, offering developers an integrated suite of audio intelligence models and a unique LLM integration framework. Founded in 2017, the company provides capabilities that extend beyond basic speech-to-text.
Its key features include:
AssemblyAI differentiates itself in several key areas:
1. Comprehensive Built-in Audio Intelligence: While Deepgram offers audio intelligence features, including sentiment analysis and summarization, AssemblyAI provides a broader and more deeply integrated suite.
The platform includes auto chapters (automatically segmenting content into logical sections with AI-generated headlines), content moderation (flagging sensitive topics with confidence and severity scores), and topic detection using the industry-standard IAB Content Taxonomy.
These features are positioned as core offerings designed to work together rather than add-ons to a primary transcription service.
2. LLM Integration Through LeMUR: AssemblyAI's LeMUR framework addresses a significant technical challenge: standard LLMs have context window limitations that typically can't accommodate transcripts from lengthy recordings. LeMUR processes up to 10 hours of audio (approximately 150,000 tokens) through intelligent segmentation and advanced prompting techniques.
This enables capabilities like customizable summarization and question-answering across long transcripts without building custom pipelines to connect speech-to-text with LLM services.
3. Broader Asynchronous Language Support: For pre-recorded transcription, AssemblyAI's Universal model supports 99 languages with automatic detection, substantially broader than Deepgram's 40+ language Nova coverage. This advantage applies specifically to batch processing workflows; real-time streaming language support is more limited.
🏅 NOTE: We also evaluated Google Cloud Speech-to-Text and AWS Transcribe for the "comprehensive features" category. While both offer strong enterprise support and ecosystem integration, AssemblyAI provides the most cohesive Speech Understanding platform that unifies transcription with audio intelligence and LLM integration for teams needing more than basic transcription.
AssemblyAI uses pay-as-you-go pricing with the same base rate for both pre-recorded and streaming transcription. Audio intelligence features are available as add-ons. Here's the breakdown:
Source: AssemblyAI
Choose AssemblyAI if:
Speechmatics is a Cambridge-based speech recognition company founded in 2006, positioning itself as a mission-critical provider for enterprises requiring flexible deployment and industry-specific accuracy. With nearly two decades of experience, the company offers mature infrastructure for organizations with stringent compliance requirements.
Key capabilities include:
Speechmatics stands out in several areas:
1. Air-Gapped Deployment With Offline Licensing: While Deepgram offers self-hosted options, Speechmatics' licensing system works in fully air-gapped environments without requiring network access. Deepgram's self-hosted documentation indicates that an active connection with their license server is required at all times.
For defense, government, and highly regulated financial services requiring complete network isolation, this difference is significant.
2. Purpose-Built Medical Transcription: Speechmatics offers specialized medical models with expanded clinical terminology, designed for ambient scribe and dictation use cases. Rather than relying on custom vocabulary boosting, these pre-built models provide faster time-to-value for healthcare transcription applications.
3. Global Language Packs: Instead of separate accent-specific models, Speechmatics developed "Global English" and "Global Spanish" packs trained on diverse accent datasets from 40+ countries. This approach uses a single model to handle all accent variations within a language.
🏅 NOTE: We also evaluated AWS Transcribe and Google Cloud Speech-to-Text. While both offer enterprise support, Speechmatics provides proven air-gapped deployment capabilities and healthcare-specific models for organizations with strict data residency requirements.
Speechmatics uses tiered pricing that varies by accuracy tier (Standard vs. Enhanced) and processing mode (real-time vs. batch). Here's the breakdown:
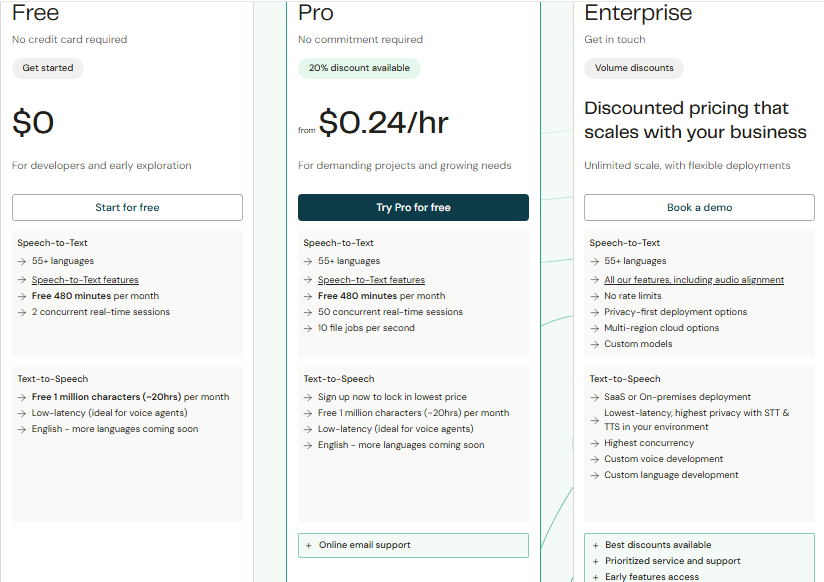
Source: Speechmatics
Choose Speechmatics if:
Rev.ai is the API arm of Rev.com, providing speech-to-text services through a developer-friendly interface that uniquely bridges AI and human transcription. The platform offers a compelling option for small businesses and startups needing reliable transcription without enterprise complexity.
Key capabilities include:
Rev.ai differentiates in several ways:
Deepgram is purely AI-driven; if accuracy falls short, the only option is manual correction.
🏅 NOTE: We also evaluated OpenAI Whisper API and AWS Transcribe free tier. While Whisper offers excellent accuracy at $0.006/minute, Rev.ai uniquely provides the human transcription safety net for small teams who need guaranteed accuracy on critical files.
Rev.ai offers straightforward batch transcription pricing with per-second billing (15-second minimum). Real-time streaming is not a primary focus. Here's the breakdown:
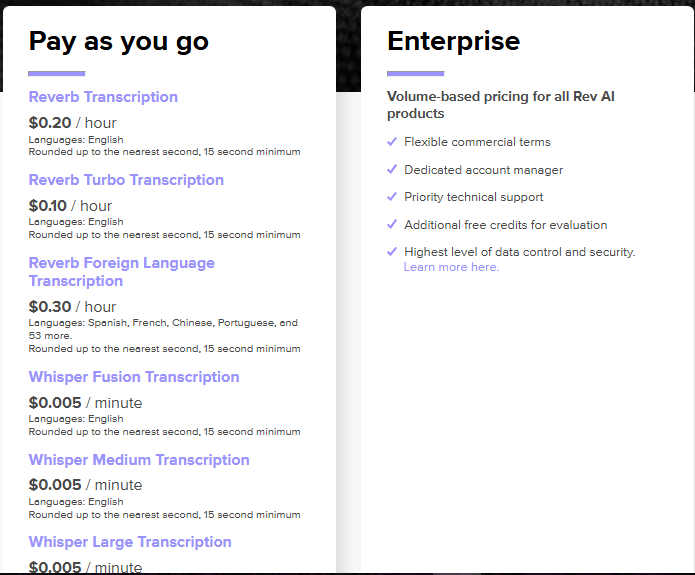
Source: Rev.ai
Choose Rev.ai if:
AWS Transcribe is an AWS-native speech recognition service that reduces vendor management overhead for teams already invested in Amazon's cloud infrastructure. Rather than integrating an external provider, organizations using S3, Lambda, and Connect can add transcription without leaving their existing ecosystem.
Key capabilities include:
AWS Transcribe stands out in several ways:
🏅 NOTE: We also evaluated Google Cloud Speech-to-Text and Azure Speech Services. While both offer strong capabilities, AWS Transcribe provides the most seamless integration for teams committed to AWS infrastructure.
AWS Transcribe uses pay-as-you-go pricing with volume discounts. Standard transcription covers both batch and streaming at the same rate. Here's the breakdown:
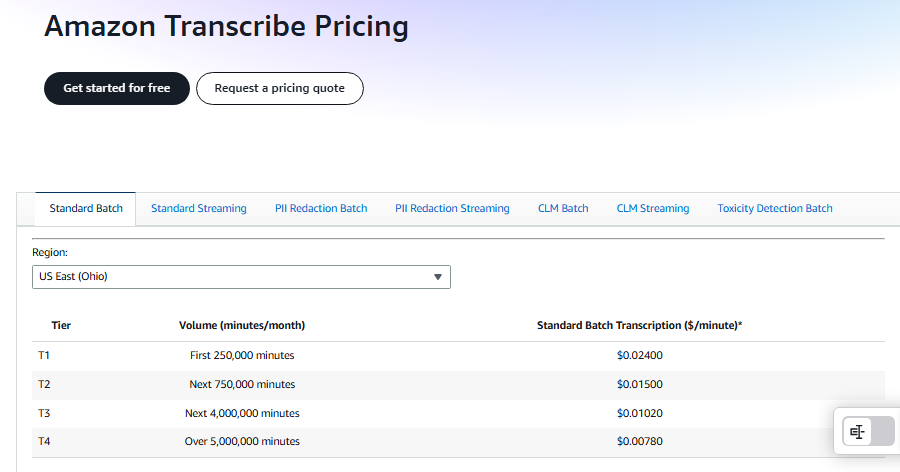
Source: AWS
Choose AWS Transcribe if:
Source: GitHub
OpenAI Whisper is an open-source ASR system released under MIT license, offering a fundamentally different proposition from commercial APIs. Teams with infrastructure expertise can significantly reduce ongoing transcription costs by deploying the model on their own hardware.
Key capabilities include:
Whisper differentiates in several critical ways:
🏅 NOTE: We also evaluated Vosk and Mozilla DeepSpeech. While both offer open-source ASR, Whisper provides strong accuracy, broad language coverage, and active community support. However, self-hosted solutions require significant infrastructure expertise, and the economics only favor self-hosting at very high volumes (typically thousands of hours per month). To evaluate whether self-hosting makes sense for a given use case, Gladia's build vs. buy calculator can help estimate total cost of ownership.
OpenAI Whisper is free to self-host, but requires GPU infrastructure. The hosted API option through OpenAI is batch-only with no real-time streaming support. Here's the breakdown:
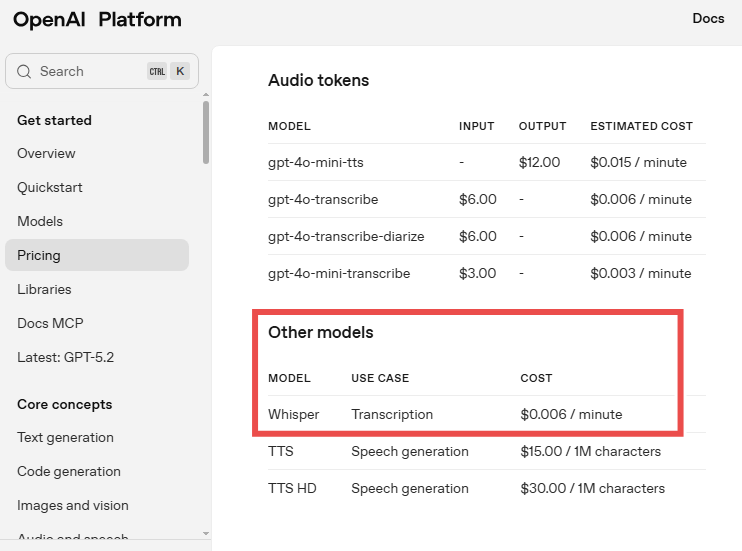
Source: OpenAI
Choose OpenAI Whisper if:
Soniox is a real-time speech-to-text and translation platform built around a single universal AI model that processes 60+ languages without requiring language-specific model switching. The platform serves teams building global voice experiences who need consistent cross-language performance with true mid-sentence translation.
Key capabilities include:
Soniox differentiates in several areas:
🏅 NOTE: We also evaluated ElevenLabs Speech-to-Text and Picovoice. While ElevenLabs is known for voice synthesis and Picovoice offers edge deployment capabilities, Soniox focuses specifically on unified multilingual transcription and real-time translation for global voice applications.
Soniox uses token-based pricing with clear separation between async and real-time modes. Translation and other features are included through the same token model. Here's the breakdown:
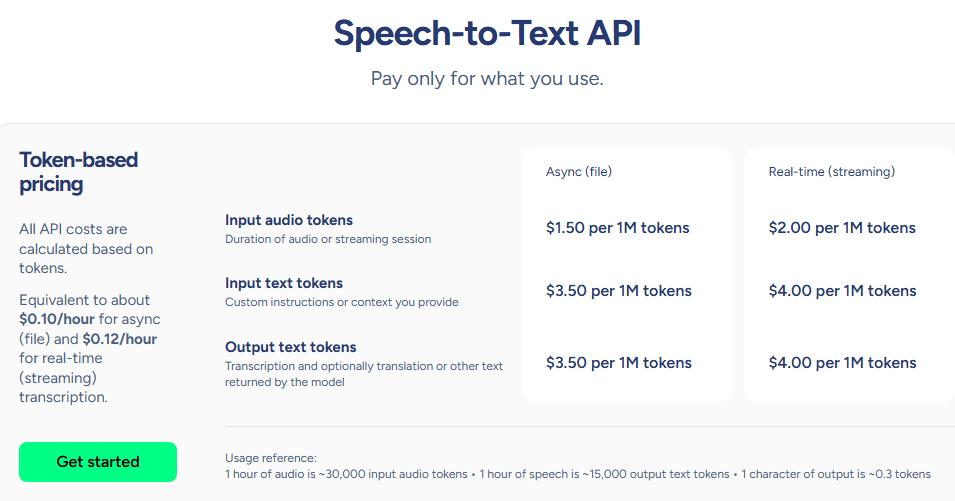
Source: Soniox
Choose Soniox if:
While Deepgram offers excellent speech-to-text performance with strong real-time capabilities and audio intelligence features, different organizations have requirements that call for specialized solutions. Here are the best alternatives based on our research across the speech-to-text market:
Remember, these alternatives aren't necessarily "better" than Deepgram; they're better fits for specific requirements. Many organizations successfully use multiple speech-to-text providers for different use cases based on language needs, accuracy requirements, and budget constraints.
Consider the specific priorities at hand when deciding which solution works best.
Ready to transcribe in 100+ languages with native code-switching and configurable privacy controls? Get started with Gladia's 10 free hours monthly and experience the difference that purpose-built multilingual support makes.






